
Linux
-
¿Será este, por fin, el año de Linux en el escritorio?

Con la llegada de cada nuevo año, se repite un fenómeno cíclico en foros, comunidades y redes dedicadas al software libre: la aparición de la frase ritual "Este sí será el año de Linux en el escritorio". Durante décadas, esta afirmación ha resonado más como una expresión de deseo que como una realidad tangible. Sin embargo, el escenario actual sugiere un cambio sustancial; esta vez, los argumentos que respaldan tal predicción parecen poseer una solidez inédita.
La omnipresencia invisible de Linux
Para comprender la situación, es necesario desmitificar la posición de Linux en el ecosistema tecnológico. Lejos de ser un sistema operativo marginal, Linux constituye la base fundamental de la infraestructura digital moderna. En la actualidad, domina sectores críticos como:
- Centros de datos y servicios en la nube.
- Computación científica y de alto rendimiento.
- Infraestructura crítica empresarial.
- Plataformas modernas de inteligencia artificial.
Cualquier usuario que utilice internet interactúa, casi con total seguridad, con sistemas Linux a diario, aunque dicha interacción ocurra de manera transparente. No obstante, existe un territorio donde históricamente no ha logrado hegemonía: el escritorio doméstico (especialmente en ofimática, multimedia y videojuegos), un espacio donde Windows ha mantenido su dominio frente a alternativas comerciales como macOS.
El factor Windows 11: Obsolescencia técnica y migración forzada
Curiosamente, el detonante más reciente a favor de Linux no proviene de su propia comunidad, sino de decisiones estratégicas de Microsoft. La finalización del soporte oficial de Windows 10 y la transición forzada hacia Windows 11 generaron inconformidad en una parte significativa de la base de usuarios.
La controversia no radica en el sistema operativo Windows 11 per se, sino en sus exigencias técnicas. Equipos relativamente recientes y perfectamente funcionales quedaron excluidos de los requisitos mínimos, enviando un mensaje claro al consumidor: si el hardware no cumple, debe ser actualizado. Esto planteó una interrogante económica y ecológica inevitable: ¿Se justifica la adquisición de un computador nuevo exclusivamente para mantener el sistema operativo?
Ante este escenario, la alternativa de migrar al ecosistema de Apple (macOS) presenta dos barreras de entrada considerables para el usuario promedio: la restricción del sistema al hardware propietario de la marca y un costo de adquisición elevado.
La madurez del ecosistema Linux
En este contexto de exclusión de hardware y altos costos, Linux emerge como una alternativa viable, dejando atrás su estigma de sistema "solo para expertos". Sus características fundamentales —código abierto, gratuidad, flexibilidad y compatibilidad con una vasta gama de hardware— se suman a una madurez técnica notable en el entorno de escritorio.
El concepto de Distribución
Para el usuario no iniciado, es vital entender que Linux no es un sistema monolítico, sino una familia de sistemas denominados "distribuciones" (distros). Cada distribución es una versión mantenida por una comunidad o empresa con una filosofía específica, abarcando desde sistemas para servidores hasta versiones para el usuario común y, más recientemente, para el entretenimiento digital.
La revolución del Gaming: Valve y la capa Proton
El cambio más disruptivo de los últimos años ha sido la optimización de Linux para videojuegos, un área que anteriormente representaba su mayor debilidad. Han surgido distribuciones diseñadas específicamente para gaming y multimedia, optimizadas para rendimiento y estabilidad, tales como:
- Pop!_OS (basada en Ubuntu).
- Nobara (basada en Fedora).
- Garuda Linux (basada en Arch).
- Bazzite (basada en Fedora).
- SteamOS (basada en Arch).
El catalizador definitivo de esta transformación fue Valve, la corporación detrás de la plataforma Steam. Al identificar su dependencia del ecosistema Windows, Valve apostó por Linux desarrollando SteamOS y, crucialmente, la tecnología Proton.
Proton actúa como una capa de compatibilidad que permite ejecutar videojuegos diseñados nativamente para Windows directamente en Linux, sin necesidad de modificar el código original del juego. Gracias a herramientas complementarias como GameMode, DXVK, VKD3D-Proton, Gamescope y MangoHud, la experiencia actual ofrece:
- Funcionamiento de la mayoría de juegos modernos.
- Rendimiento competitivo.
- Fluidez sorprendente.
Discusión y Conclusión
Hoy, Linux ofrece un rendimiento sólido, estabilidad superior, menor obsolescencia forzada y un control real sobre el equipo. Tras años de promesas, las condiciones técnicas finalmente se han alineado.
Si bien esto no implica que Linux reemplazará a Windows en el corto plazo de manera absoluta, sí marca un hito importante: por primera vez, elegir Linux en el escritorio no conlleva sacrificar experiencia de usuario, comodidad ni entretenimiento.
La interrogante final recae sobre el usuario: si se dispone de un computador competente y se desea evitar el cambio de hardware por exigencias artificiales, valorando la libertad del sistema, ¿existe la disposición para probar Linux? Tal vez, en esta ocasión, la vieja frase ritual tenga razón.
Y tu que nos lees, ¿Estarías dispuesto a probar alguna de estas distros de Linux?
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Bitácora de Laboratorio: HomeLab - Montaje Dinámico de Archivos en Red Local (sin IPs fijas ni dramas de DNS)

Entorno: Linux (Familia RHEL: Fedora) · SSHFS · Autofs · Monitoreo ARP
Nivel: Entusiasta Cacharrero / Nivel de Automatización: “vago pero eficiente”El problema: IPs que bailan y routers que no ayudan
En la mayoría de nuestras casas, el router del ISP hace lo que quiere: asigna IPs dinámicas y no nos deja tocar el DNS local. Si intentas montar una carpeta remota, lo más probable es que el enlace se rompa en cuanto el router decida darle otra IP a tu servidor.
Esta bitácora documenta una solución pragmática y basada en eventos: 1. Descubrimiento pasivo: Escuchamos al kernel para saber cuándo aparece una MAC específica. 2. Resolución local: Actualizamos
/etc/hostsal vuelo cuando el dispositivo se conecta. 3. Montaje bajo demanda:autofsmonta la carpeta por SSHFS solo cuando realmente entras en ella.Paso 1 — Resolución de nombres sin servidor DNS
En lugar de montar un servidor DNS completo (que es un lío), usamos un pequeño script que “escucha” la red y actualiza tu
/etc/hostssolo cuando tus cacharros cambian de estado.1.1 Lo básico
sudo dnf install arp-scan inotify-tools autofs fuse-sshfs1.2 Configura
sudosin contraseñaPara que el script pueda actualizar
/etc/hostsy escanear la red sin pedirte la clave cada 5 minutos, necesitamos darle permisos específicos en/etc/sudoers.d/lan-watch:sudo visudo /etc/sudoers.d/lan-watchAñade estas líneas (cambiando
tu_usuariopor tu nombre de usuario real):tu_usuario ALL=(ALL) NOPASSWD: /usr/sbin/arp-scan tu_usuario ALL=(ALL) NOPASSWD: /usr/bin/sed tu_usuario ALL=(ALL) NOPASSWD: /usr/bin/tee1.2 El Script “Mágico” —
~/bin/lan-watch.shEste script es súper eficiente. No está escaneando todo el rato; se queda esperando a que el kernel le diga: “Oye, este vecino acaba de cambiar de estado”.
#!/bin/bash PEERS_DIR="$HOME/peers" MOUNT_BASE="$HOME/peers/homelan" # Detectamos la interfaz activa automáticamente IFACE=$(ip route get 8.8.8.8 | grep -Po '(?<=dev )(\S+)') [ -z "$IFACE" ] && IFACE=$(ip link show | grep -m 1 "state UP" | awk -F': ' '{print $2}') # Mapa de MAC → Nombre (Pon aquí las MACs de tus máquinas) declare -A MAC_NAMES=( ["00:11:22:33:44:55"]="servidor-pro" ["66:77:88:99:aa:bb"]="mi-nas" ) rebuild_hosts() { BLOCK="# homelan-start\n" for f in "$PEERS_DIR"/*.txt; do [ -f "$f" ] || continue BLOCK+="$(cat $f)\n" done BLOCK+="# homelan-end" sudo sed -i '/# homelan-start/,/# homelan-end/d' /etc/hosts echo -e "$BLOCK" | sudo tee -a /etc/hosts > /dev/null } update_peer() { local NAME=$1 local IP=$2 local ACTION=$3 # "online" u "offline" if [ "$ACTION" == "online" ]; then echo "$IP$NAME.internal$NAME" > "$PEERS_DIR/$NAME.txt" echo "[$(date)]$NAME está ONLINE:$IP ($IFACE)" else if [ -f "$PEERS_DIR/$NAME.txt" ]; then rm -f "$PEERS_DIR/$NAME.txt" echo "[$(date)]$NAME está OFFLINE, quitando registro" # Desmontaje "perezoso" para que no se cuelgue el sistema if mountpoint -q "$MOUNT_BASE/$NAME" 2>/dev/null; then sudo umount -l "$MOUNT_BASE/$NAME" fi fi fi rebuild_hosts } # Sincronización inicial al arrancar SCAN=$(sudo arp-scan -I "$IFACE" --localnet 2>/dev/null) for MAC in "${!MAC_NAMES[@]}"; do NAME="${MAC_NAMES[$MAC]}" IP=$(echo "$SCAN" | grep -i "$MAC" | awk '{print $1}') [ -n "$IP" ] && update_peer "$NAME" "$IP" "online" || update_peer "$NAME" "" "offline" done # Escuchando eventos del kernel en tiempo real ip monitor neigh dev "$IFACE" | while read -r event; do IP=$(echo "$event" | awk '{print $1}') MAC=$(echo "$event" | grep -oi '[0-9a-f:]\{17\}') STATE=$(echo "$event" | grep -oE "REACHABLE|STALE|FAILED|DELETE") [ -z "$STATE" ] && continue NAME="" [ -n "$MAC" ] && NAME="${MAC_NAMES[${MAC,,}]}" [ -z "$NAME" ] && NAME=$(basename "$(grep -l "$IP" "$PEERS_DIR"/*.txt 2>/dev/null)" .txt) [ -z "$NAME" ] && continue case "$STATE" in REACHABLE|STALE) update_peer "$NAME" "$IP" "online" ;; FAILED|DELETE) update_peer "$NAME" "$IP" "offline" ;; esac done1.3 El servicio que lo mantiene vivo
Crea
~/.config/systemd/user/lan-watch.service:[Unit] Description=LAN ARP watcher After=network-online.target [Service] ExecStart=%h/bin/lan-watch.sh Restart=always [Install] WantedBy=default.targetLuego dale vida con:
systemctl --user enable --now lan-watch.service.
Paso 2 — Configuración de SSH y Autofs
2.1 Generar clave SSH dedicada para el homelab
ssh-keygen -t ed25519 -f ~/.ssh/homelab_key -C "homelab autofs"2.2 Copiar la clave pública a cada máquina remota
ssh-copy-id -i ~/.ssh/homelab_key -o IdentitiesOnly=yes usuario@host_remoto.internal2.3 El gran truco: SSH para Root
autofs corre como root, pero nosotros queremos usar nuestras llaves SSH de usuario.
- Autoriza a Root: Root tiene que confiar en la máquina remota. Conéctate una vez a mano usando sudo:
sudo ssh -i /home/tuusuario/.ssh/homelab_keyEsta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. - Permisos: Asegúrate de que
/etc/fuse.conftenga habilitadouser_allow_other.
2.4 El mapa de Autofs — /etc/auto.homelan
Aquí usamos unos flags específicos para que la conexión no se quede “colgada” si el servidor se apaga.
servidor-pro -fstype=sshfs,port=22,IdentityFile=/home/tuusuario/.ssh/homelab_key,IdentitiesOnly=yes,uid=1000,gid=1000,allow_other,StrictHostKeyChecking=no,reconnect :Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. :/home/tuusuarioStrictHostKeyChecking=no: Para que no falle si la máquina remota cambia de identidad en tus pruebas.reconnect: Intenta reconectar el túnel SSH automáticamente si se cae la conexión de red.uid=1000,gid=1000: Para que tu usuario sea el dueño de los archivos montados.
2.5 El gran truco: SSH para Root
autofscorre como root, pero nosotros queremos usar nuestras llaves SSH de usuario.- Autoriza a Root: Root tiene que confiar en la máquina remota. Conéctate una vez a mano usando sudo:
bash sudo ssh -i /home/tuusuario/.ssh/homelab_keyEsta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. - Permisos: Asegúrate de que
/etc/fuse.conftenga habilitadouser_allow_other.
2.6 El mapa de Autofs —
/etc/auto.homelanAquí usamos unos flags específicos para que la conexión no se quede “colgada” si el servidor se apaga.
servidor-pro -fstype=sshfs,port=22,IdentityFile=/home/tuusuario/.ssh/homelab_key,IdentitiesOnly=yes,uid=1000,gid=1000,allow_other,StrictHostKeyChecking=no,reconnect :Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. :/home/tuusuarioStrictHostKeyChecking=no: Para que no falle si la máquina remota cambia de identidad en tus pruebas.reconnect: Intenta reconectar el túnel SSH automáticamente si se cae el WiFi.uid=1000,gid=1000: Para que tu usuario sea el dueño de los archivos montados.
Paso 3 — ¿Funciona? (Verificación)
- Resolución: Escribe
getent hosts servidor-pro.internaly debería darte la IP actual. - Visibilidad: Haz un
ls ~/peers/homelan/y deberías ver la carpeta (aunque esté vacía). - Montaje: Entra en ella:
cd ~/peers/homelan/servidor-pro. El montaje SSHFS debería activarse solo.
Tabla de “Primeros Auxilios”:
Síntoma Solución rápida No such file or directoryRevisa que haya un :antes del nombre de usuario en el mapa de autofs.Se queda colgado al entrar Usa umount -ly mira si el servidor sigue vivo.Permission deniedMira si user_allow_otherestá descomentado en/etc/fuse.conf.
Conclusiones de diseño
- Cero estrés: No hay polling, el script no consume nada mientras espera eventos del kernel.
- Limpio: Usamos
.internalque es el estándar oficial para redes privadas (formalmente correcta según RFC 9476 - 2023). - Ordenado: El script limpia los montajes “fantasma” cuando apagas un servidor.
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
- Autoriza a Root: Root tiene que confiar en la máquina remota. Conéctate una vez a mano usando sudo:
-
Cloud + Open Source + Azure
Los invitamos una vez más a este nuevo taller donde aprenderemos como configurar y desplegar nuestro entorno de desarrollo web Open Source soportado en la plataforma Microsoft Azure.
Nivel: Básico
- Cuándo
- Sede
- Vivelab Bogotá Av el dorado Carrera 45 No 26-33
- ¡Los esperamos!
Inscripciones
https://www.eventbrite.es/e/entradas-cloud-open-source-azure-24751616752
¡Entrada libre!
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Cómo montar particiones LVM desde el modo de rescate (CentOS/Fedora) { Notas de Laboratorio }
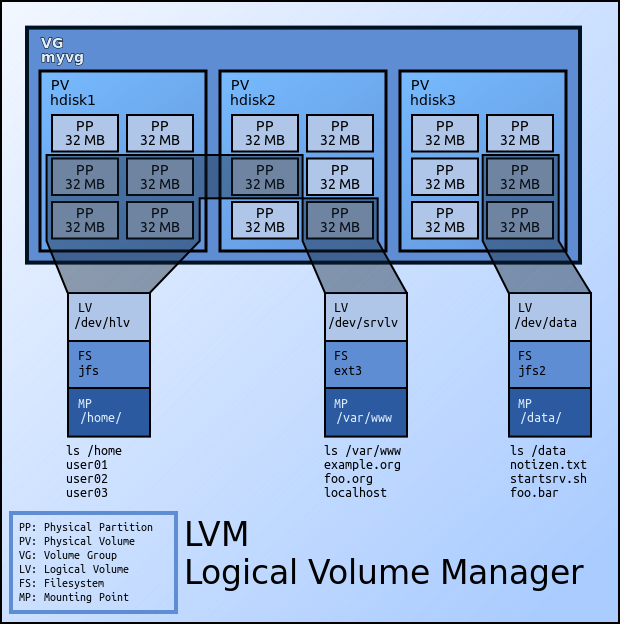
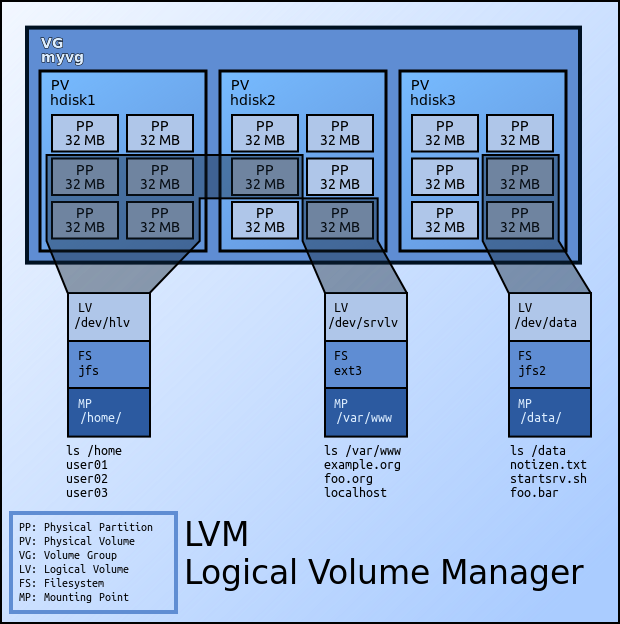
Simplemente cómo nota de laboratorio, porque ya me ha pasado varias veces (y necesito anotarlo en algún lado), en un equipo que usa fedora (también sirve para CentOS) y tiene usuarios creativos, de esos que lo apagan a patadas, dejo para el registro el proceso para montar un Volumen Lógico.
Después de que el usuario deja el equipo en modo de solicitud de restauración (esa consola negra que pide una constraseña administrativa para escanear los discos y restaurar el sistema)...si se tiene la fortuna de recordar la clave de root, no se tiene claro cómo montar ese maldito y sensual volumen lógico que se hizo cool al momento de instalación (LVM es una nota, pero si se retoma un equipo que no se ha tocado en años, puede quedar uno perdido por unos momentos).
El procedimiento en consola de recuperación es:
Revisar los volúmenes lógicos de la máquina:
lvm vgscan -v
Activar los volúmenes lógicos:
lvm vgchange -ay
Listar los volúmenes lógicos disponibles:
lvm lvs -all
Montar el volúmen requerido:
mount /dev/volgroup/logvol /mountpoint
Con el volúmen detectado y siendo capaces de montarlo, ya se puede recuperar al menos la información.
Si por algún motivo se imaginan que este procedimiento es mio...pueees nop, agradezco al amigo Jim Zimmerman por hacer la tarea de registrarlo en su sitio, al menos aquí lo tienen en español, aunque con los comandos eso es irrelevante, y reitero, es una nota personal para no andar buscando en google lo mismo, cada vez que se le hace el favor a mi vecina ( "favor" :P...cuando se hace al derecho, queda uno como el Neo del barrio obrero, la consola negra asusta y si se saben par cosillas se descresta jejeje! ).
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Décima Jornada de Software Libre - Uniminuto Villavicencio

El próximo 22 de octubre estaremos acompañando a nuestros amigos de Uniminuto Villavicencio en la décima jornada de software libre con la charla titulada Linux para seres humanos (Una visión desde lo cotidiano).
El objetivo del evento es fomentar la apropiación de software libre como alternativa de desarrollo de proyectos informáticos y como modelo de negocio viable en la industria del software.
Las actividades se llevaran a cabo el día viernes 21 y sábado 22 de octubre del año en curso en el auditorioCorocoras en el Parque de la Vida COFREM.
http://www.uniminuto.edu/web/llanos/-/decima-jornada-de-software-libre
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Entornos de trabajo para ciencia de datos, instalando R-Studio y Anaconda en Ubuntu Linux 18.04


La ciencia de datos o “Data Science” como se le denomina en ingles, es una de las áreas que mayor interés ha despertado en últimos años, siendo descrita por muchos expertos como una de las áreas de mayor relevancia laboral durante la próxima década.
Pero en sí ¿que es la ciencia de datos?; La ciencia de datos es un área de estudio interdiciplinaria que usa métodos científicos, procesos matemáticos y algoritmos computacionales, con el objetivo de obtener información, conocimiento y representación de comportamientos significativos basados en datos de diferentes fuentes y tipos. Esta ciencia se encuentra muy relacionada con otras áreas igualmente destacadas recientemente, como el Big Data o el Machine Learning. Vinculando a su vez conceptos más tradicionales como lo son las bases de datos (relacionales y no relacionales) y un uso extensivo de métodos y técnicas estadística.
Por lo anterior y con el objetivo de adentrarnos en el estudio de este interesante tema, a continuación describiremos como instalar dos de los principales entornos de desarrollo para ciencias de datos, sobre nuestro Ubuntu Linux 18,04 LTS Bionic Beaver.
Para empezar describiremos el proceso de instalación de R Studio un IDE especializado para el lenguaje de programación R, lenguaje especialmente diseñado para el desarrollo de estadística computacional y graficación.
1 - Instalación de R Studio
Antes de instalar R Studio necesitaremos instalar en nuestro sistema el paquete r-base que provee el lenguaje de programación R sobre el cual trabajara nuestro IDE.
Abrimos una terminal o consola “ctr + alt + t” e introducimos los siguientes comandos:
$ sudo apt update sudo
$ apt -y install r-baseR Studio esta disponible para dos de las principales distros de Linux; Fedora y Ubuntu. Para este tutorial instalaremos la versión de R Studio para Ubuntu 16,04+/Debian 9+, la cual podemos descargar del siguiente enlace: https://www.rstudio.com/products/rstudio/download/#download
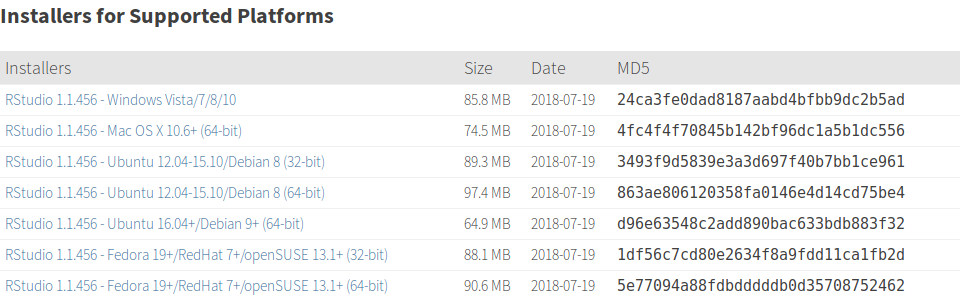
Una vez realizada la descarga volvemos a nuestra terminal o consola e introducimos los siguientes comandos:
$ cd Descargas$ lsrstudio-xenial-1.1.456-amd64.debLa carpeta descargas puede variar de acuerdo a la configuración o la instalación de su sistema así que podría tener Descargas o Downloads*
Una vez identificado el paquete procedemos a su instalación:
$ sudo gdebi rstudio-xenial-1.1.456-amd64.debY a continuación podremos ejecutar R Studio desde la consola con el siguiente comando:
$ rstudio
O bien desde el menú de aplicaciones: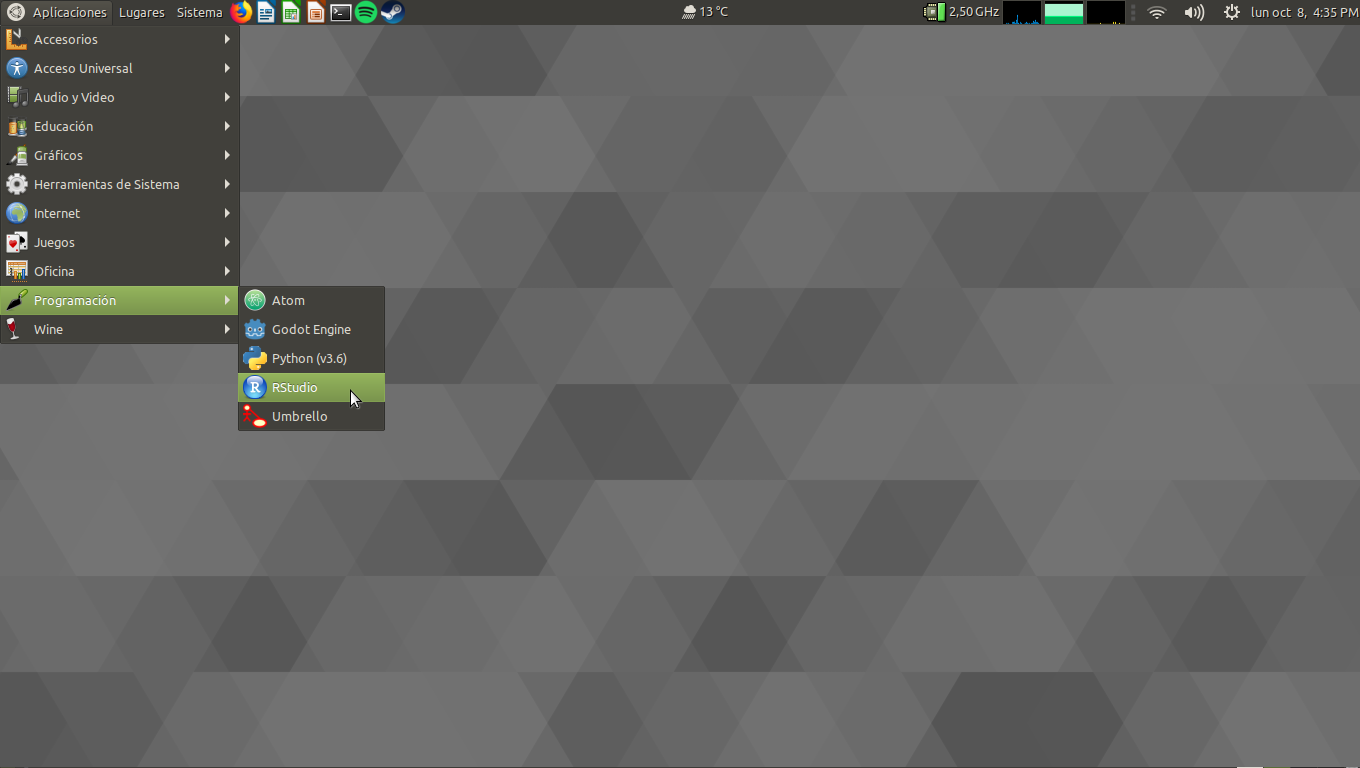
2 – Instalación de AnacondaAnaconda es una distribución de Python y R especializada en ciencia de datos “Data Science” y “Machine Learning” orientada al procesamiento de datos a gran escala. Cuenta con su propio administrador de paquete e integra más de 250 librerías y utilidades especializada para el trabajo en ciencia de datos.
Para comenzar, lo primero que tenemos que hacer es dirigirnos a la pagina de Anaconda y descargar el script de instalación. Podemos hacer esto dando clic en el siguiente enlace: https://www.anaconda.com/download/#linux (esta descarga puede tomar algunos minutos según la velocidad de su conexión)

Una vez realizada la descarga volvemos a nuestra terminal o consola e introducimos los siguientes comandos:
$ cd Descargas$ lsAnaconda3-5.3.0-Linux-x86_64.shIdentificado el paquete, volvemos a la terminal e iniciamos el proceso de instalación por medio del siguiente comando:
$ sh Anaconda3-5.3.0-Linux-x86_64.shAl ejecutarlo se despegará el siguiente mensaje:
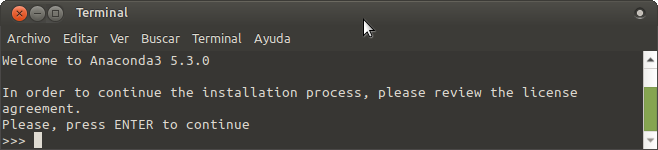
Oprimimos la tecla Enter para ver todos los términos de la licencia y finalmente escribimos “yes” para aceptar y continuar con el proceso de instalación.
Posteriormente nos solicita confirmar la ubicación de los archivos de instalación, para el presente caso usaremos los predeterminados por lo que simplemente oprimiremos la tecla Enter
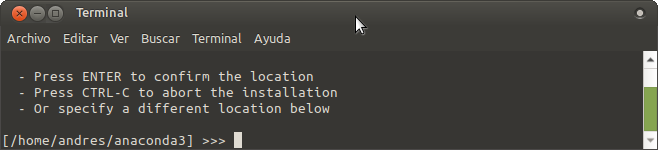
A continuación nos pregunta si deseamos que el instalador inicialice Anaconda3 en nuestro bashrc a lo que en este caso diremos que si, “yes”.
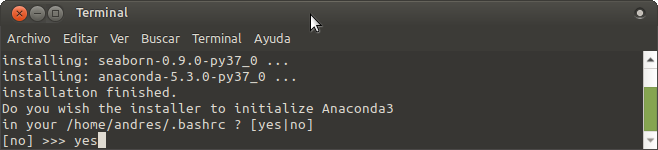
Una vez finalizada la instalación de Anaconda, el instalador nos preguntará si deseamos instalar el editor Visual Studio Code, con lo que conforme a sus preferencias ustedes podrán aceptar o seguir adelante y utilizar su editor preferido.
Finalmente procedemos con la activación de la instalación de anaconda ejecutando el siguiente comando:
$ source ~/.bashrcy la confirmamos con:
$ conda info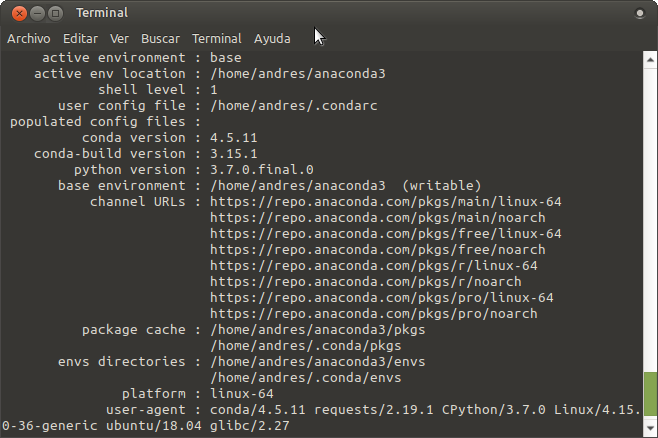
Ok, ya esta instalado nuestro Anaconda, pero aun falta el paso final, la cereza del pastel. Y es desplegar nuestro entorno grafico de configuración y trabajo desde el navegador.Para hacer esto simplemente ejecutamos el siguiente comando desde nuestra terminal y tendremos todo el poder de Anaconda a nuestra disposición.
$ anaconda-navigator
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Instalando Django 2.0 en Ubuntu Linux 16.04 LTS {Notas de Laboratorio}

El pasado 2 de Diciembre fue liberada la version 2.0 de Django, Framework para desarrollo web escrito en Python.
Es por esto que en OpenSAI nos dimos a la tarea de hacer un pequeño resumen de como instalarlo de manera facil en nuestro Ubuntu Linux 16.04.
Antes de instalar Django verificamos cumplir los requerimientos mínimos del sistema.
Para la version 2.0 es nesario contar con Python 3.5 instalado.
Luego Procedemos a instalar pip3
1 - Como súper usuario ejecutamos:
:~$ apt install python3-pip
2 - Una vez instalado pip procedemos a actualizarlo a la ultima versión disponible
$source djangoprojects/bin/activate
:~$ pip3 install -U pip
3 - Una vez actualizado pip procedemos a instalar como súper usuario el virtualenv para ejecutar las aplicaciones Django de forma independiente al python del sistema.
:~$ pip3 install virtualenv
4 - Una vez instalado correctamente el virtualenv procedemos a crear el directorio donde se alojara la instancia virtual de python.
:~$virtualenv ENV
5 - A continuación procedemos a activar el ambiente virtual de python con el siguiente comando
:~$source djangoprojects/bin/activate
6 - Sabremos que el entorno virtual esta activado cuando veamos que antes del nombre de nuestra terminal aparece el nombre de nuestro ambiente virtual entre paréntesis, ejem: (djangoprojects) usuario@maquina:~$
7 - Para salir del entorno virtual simplemente ejecutamos el comando:
:~$ deactivate
8 - Finalmente procedemos a instalar Django en nuestro entorno virtual.
:~$ pip3 install Django
9 - Una vez instalado Django procedemos a comprobar que en efecto la instalación fue exitosa, ejecutando el siguiente script desde el interprete de python.
:~$python3
>>> import django
>>> print(django.get_version())
Finalemente al ejecutarlo deberemos de obtener el numero de la versión de Django que acabamos de instalar.
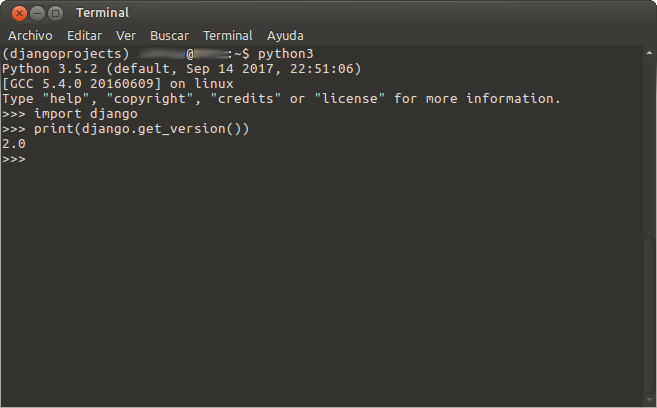
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Linux para humanos
En este taller hablaremos sobre Linux, su historia, funcionalidades y como aprender a sacar el máximo provecho del sistema operativo del pingüino desde la óptica de un usuario final
- Cuándo
- Sede
- Vivelab Bogotá Av el dorado Carrera 45 No 26-33
- Inscriociones: http://bit.ly/1X4lRUM
- Entrada libre previa inscripción.
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Linux para humanos - Resultados

El pasado 18 de mayo se llevo a cabo en las instalaciones del Vivelab Bogotá la más reciente versión de nuestro taller "Linux para seres humanos" en donde los asistentes reconocieron los conceptos básicos que rodean la filosofia de uso y funcionamiento del sistema operativo del pingüino y finalmente se untaron las manos aprendiendo a configurar su sistema para uso casero con todas las herramientas disponibles para el usos cotidiano de su PC junto con varias alternativas libres a programas se uso frecuente pero de licencia privativa.
Un agradecimiento muy especial a todo el equipo de Vivelab Bogotá por su colaboración.



En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Mejorando la calidad de la captura de sonido/micrófono con PulseAudio


Hoy en día es muy común desarrollar actividades que implican la captura de sonido por medio de un micrófono. Conversar con nuestro amigos por medio de alguna aplicación vía internet, grabar audio para una presentación o probar nuestras cualidades artísticas cantando nuestra canción favorita. Todas estas son situaciones cotidianas, pero para algunos usuarios de Linux pueden llegar a ser frustrantes debido a la calidad del sonido obtenido.
Es muy cierto que la calidad del micrófono es un factor decisivo a la hora de grabar un buen audio y más si se desea obtener un nivel de calidad tipo estudio, aun así a continuación explicaremos algunos trucos que podrán ayudar a mejorar la calidad de tus grabaciones incluso si tu micrófono no es el mejor.
Nota: Los comandos a continuación descritos se basan en Ubuntu Linux 16,04 LTS aunque deberían funcionar sin grades diferencias en la mayoría de distros.
Cancelación de eco y reducción automática de ruido.
Para empezar debemos hacer unos pequeños cambios en el archivo de configuración del servidor Pulse. Para entrar a editar este archivo simplemente deberemos ejecutar el siguiente comando con permisos de administrador:
-
sudo nano /etc/pulse/default.pa
Ingresamos la contraseña de administrador y procedemos añadiendo las siguientes lineas al final del archivo:
-
load-module module-echo-cancel source_name=noechosource sink_name=noechosink -
set-default-source noechosource -
set-default-sink noechosink
Finalizamos oprimiendo la combinación de teclas CTRL+X donde se nos preguntará sí deseamos guardar los cambios a lo que responderemos “Si”.
Estando nuevamente en la consola reiniciaremos el servidor Pulse con el siguiente comando:
-
pulseaudio -k
Una vez realizado este proceso podemos ir al panel de control de sonido de nuestra distro en la que veremos una nueva opción que nos indica que la configuración se ha efectuado adecuadamente.
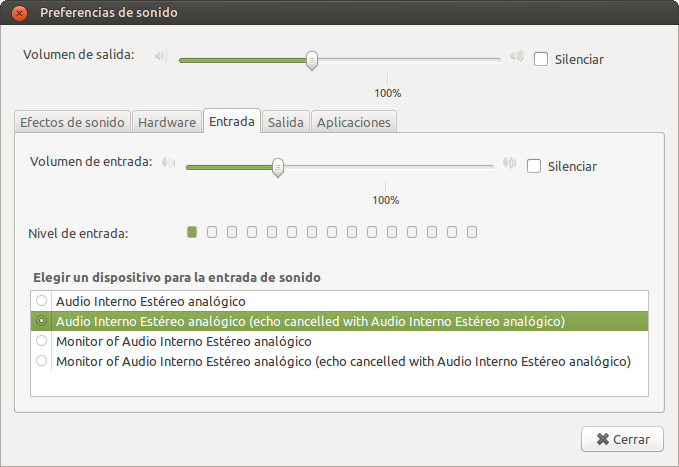
Portada: “Microphone” by Grantis licensed under CC BY 2.0
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
-
Pomodoro en Bash en menos de 100 líneas (newbies)
Cuando se tienen muchas cosas que hacer, a veces no se sabe por donde empezar, se arma un interbloqueo y hasta aparece la procrastinación. Una técnica de trabajo que apoya esa situación es la del Pomodoro. Se fraccionan las tareas en ciclos de al menos 25 minutos (divide y vencerás), donde se ejecuta sólo una tarea, con toda la concentración del mundo (está demostrado que el multitasking en los seres humanos es puro cuento...bueno las mujeres pueden hacerlo, pero no es la norma 😜😇). Al finalizar el día si se hace responsablemente la labor, el nudo comenzará a simplificarse, desde luego conviene llevar un registro, lo que en sistemas de software sería un log.
Hay una infinidad de aplicaciones para trabajar Pomodoro, sin embargo, por puro placer y como ejercicio práctico para el aprendizaje de Bash y conceptos básicos de programación, publicamos un Pomodoro en menos de 100 líneas de código en Bash. Quién aprenda a manejar realmente este sistema de scripting y una Terminal Linux, tendrá una ventaja competitiva en los sistema industriales de software actuales.
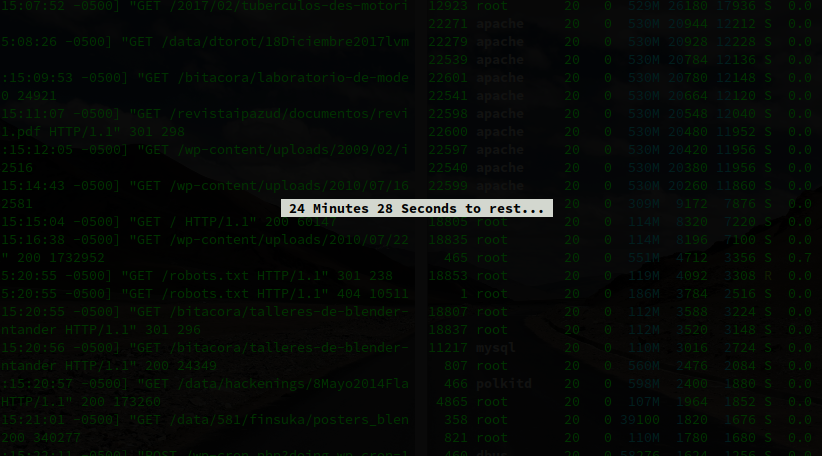
Todo arranca con un comando básico y sencillito:
sleep 1
El comando sleep es nativo de la consola de Linux que nos detiene la ejecución de un script, en este caso precisamente por un segundo. Si se puede hacer eso podemos organizar un loop (ciclo repetitivo) que nos cuente hasta un minuto:
for (( SECSCount=1; SECSCount<=60; SECSCount++ ))
do
tput clear
print_timer " $(($MINS-$MINSCount)) Minutes " "$((60-$SECSCount)) Seconds to rest... " "$(tput lines)" "$(tput cols)"
sleep 1
doneSe tiene un ciclo para 60 segundos, en cada paso se limpia la pantalla, se imprimen los minutos, segundos, no hay que dejarse despistar por tput que es un comando que permite manejar los parámetros de comportamiento de la terminal:
tput lines retorna el número de líneas disponiblesn en la terminal actual tput cols retorna el número de columnas disponibles en la terminal actual tput clear limpia la pantalla tput bold coloca los caracteres de la terminal en negrilla tput cut Y X posiciona el cursor de la pantalla en la coordenada X, Y (filas, columnas) tput setaf cambia color del fondo del texto tput rev invierte el coloreado de los caracteres (color en fondo y no en las letras) tput sgr0 reinicia los parámetros de la terminal (si no se usa al terminar la ejecución, la terminal queda con otros colores...) tput civis oculta el cursor de la terminal tput cnorm muestra de nuevo el cursor y print_timer es una función creada al inicio del script para imprimir el reloj (el letrero en pantalla con los minutos y segundos...después la miramos), esta función recibe como parámetros encerrados en comillas dobles, el contador de los minutos, el contador de los segundos, el tamaño en filas y en columnas de la terminal. El objetivo es que el reloj siempre se presente en el centro de la pantalla.
Cómo estámos contando el tiempo en reversa (si tenemos 25 minutos para el pomodoro, vamos hacia atrás hasta llegar a cero...), a 60 le restamos los segundos del contador y a los minutos totales, le restamos los minutos del contador de minutos de nuestro script (...así se hace un ciclo repetitivo for en bash...¡vamos! quién sepa programar en Bash no estaría leyendo este contenido, por eso lo aclaramos).
Bueno, pero un minuto tiene 60 segundos, luego el anterior ciclo debería estar en otro externo para contar minutos y segundos:
for (( MINSCount=1; MINSCount<=$MINS; MINSCount++))
do
for (( SECSCount=1; SECSCount<=60; SECSCount++))
do
tput clear
print_timer " $(($MINS-$MINSCount)) Minutes " "$((60-$SECSCount)) Seconds to rest... " "$(tput lines)" "$(tput cols)"
sleep 1
done
doneEl ciclo externo cuenta los minutos, el interno los segundos. $MINS es una variable que guarda el primer parámetro recibido desde la consola de Linux por nuestro script.
Hay que aclarar que en la terminal del sistema, nuestro script se ejecuta asi:
./chontoBash.sh NumMinutesToWork "My Task to work in double quotes..."
el ./ le indica al sistema Linux que ejecute el script chontoBash.sh del directorio actual, NumMinutesToWork...simplemente es un número de minutos a contar, "My Task to work in double quotes..." es la tarea que se registrará como ejecutada. Entonces se reciben dos parámetros, que dentro del script se validan asi:
if [[ $# != 2 ]]; then
tput bold; echo Error in arguments...; tput sgr0;
echo
print_help
exit 1
fiif ! [[ $1 =~ ^[0-9]+$ ]]; then
tput bold; echo...how many minutes do you like to work?; tput sgr0;
echo
print_help
exit 1
fiTenemos dos comparaciones, el primer if valida que desde la terminal de linux nos entreguen (2) dos parámetros, el segundo if valida que el primer parámetro sea un número entero. Son validaciones básicas, obviamente se pueden mejorar. Si ocurre alguna de las dos exepciones el programa termina con exit 1 (programa o script aquí son sinónimos...ya ves tú, estás programando en Bash).
Una función en Bash se crea así:
print_help (){
echo USAGE FROM TERMINAL:
echo ./chontoBash.sh NumMinutesToWork \"My Task to work in double quotes...\"
echo If not exist, chonto will create the log file log.chonto, csv file to make data analytics:
echo "TimeStamp, TotalMinutes, Task worked..., status: completed (FULL) or incomplete task (BREAK)"
echo "TimeStamp, TotalMinutes, Task worked..., status: completed (FULL) or incomplete task (BREAK)"
echo "TimeStamp, TotalMinutes, Task worked..., status: completed (FULL) or incomplete task (BREAK)"
echo .
echo .
echo .
}La ventaja es que para imprimir en pantalla todas estas líneas con el comando echo, una vez creada la función, sólo tengo que llamarla: print_helpcuántas veces quiera (el nombre de la función tu te lo inventas), esto ahorra trabajo, y mejora la organización del script.
Las otras funciones del script son:
log_chonto_break (){
end_time=$( date '+%s' )
echo $(date +"%F %H:%M:%S"), $((($end_time - $1) / 60)) Mins, "$2", BREAK >> log.chonto
mplayer glass.ogg > /dev/null 2>&1
tput clear
echo "Unfinished task logged :("
tput cnorm
exit 1
}log_chonto (){
end_time=$( date '+%s' )
echo $(date +"%F %H:%M:%S"), $((($end_time - $1) / 60)) Mins, "$2", FULL >> log.chonto
mplayer glass.ogg > /dev/null 2>&1
tput clear
echo "Task finished logged :)"
}print_timer (){
#center the timer text, centering the cursor in Y/2:X/2-((text length)/2)
tput cup $(($3/2)) $((($4/2)-($(expr length "$1 $2")/2)))
tput bold; tput setaf $((1 + RANDOM % 10)); tput rev; echo "$1$2"; tput sgr0;
}print_timer se encarga de centrar el cursor calculando primero el tamaño del reloj (cuántas letras tiene nuestro reloj para que quede centrada, verticalmente y horizontalmente), el RANDOM con el módulo es para jugar los colores de impresión en pantalla, hace que cada segundo estos cambien.
log_chonto detiene el reloj y registra en el archivo log.chonto la tarea terminada. La magia de los dos >> actúa como una redirección de los datos, permite que si el archivo log.chonto no existe se cree, y si existe agregue la linea de registro al final del mismo. Registrando en esa línea, la marca de tiempo, el tiempo ejecutado en minutos, el texto descriptivo de la tarea, la palabra FULL indica que la tarea se ejecutó en su totalidad...que no se oprimió CTRL + C.
¿Qué pasa con el CTRL+C? que hay que capturarlo y asociarle una función que se ejecutará cuando ocurra. Esa función es log_chonto_break, hace lo mismo que log_chonto, pero registra en log.chonto la palabra BREAK para indicar que NO se terminó la tarea, junto con el tiempo parcial ejecutado. El programa termina con el correspondiente aviso en terminal de carita triste: echo "Unfinished task logged :("...log_chonto por el contrario SI imprime carita feliz.
La interrupción de CTRL+C se captura así:
trap 'log_chonto_break "$start_time" "$2"' SIGINT
¡Ahhh bueno!...hay que tener mplayer instalado (búscalo en tu distribución de Linux preferida), para reproducir la campanita al terminar, para eso es el archivo de sonido glass.ogg
trap (comando nativo de Bash) recibe como parámetro el nombre de la función a ejecutar (log_chonto_break), pero esta función a su vez recibe como parámetros el tiempo de inicio registrado y el nombre de la tarea que se le envío por consola a nuestro script...almacenado en la variable $2.
Para anotar: si un script recibe tres parámetros estarían internamente guardados en $1 $2 $3. A su vez cuando una función como las que mostramos, recibe parámetros, para ella quedarían guardados en $1, $2, $3...etc. y sólo existirían en su espacio de función, por eso los corchetes. Es como una caja negra, un script, dentro de un script.
Al ejecutar un script, estas funciones no se ejecutarían automáticamente, sólo lo harían cuando se llamen explícitamente, entonces, las primeras líneas reales de ejecución de nuestro programa (obviando los if de validación), serían:
MINS=$1
start_time=$( date '+%s' )En $MINS queda guardado nuestro primer parámetro recibido desde la terminal Linux, los minutos a ejecutar (hay que usar el símbolo $ cuando se quiera llamar su contenido), y start_time arranca nuestro reloj. Si todo sale bien, la última línea de ejecución es:
log_chonto "$start_time" "$2"
Es un llamado a la función de guardado en log.chonto, que recibe como parámetros el tiempo de inicio y el nombre de la tarea. El archivo log.chonto es un archivo separado por comas, que puede usarse en otros sistemas (hasta en el mismo office...bueno, mejor LibreOffice) para generar analíticas.
El script completo sería el siguiente:
#!/bin/bash
print_help (){
echo USAGE FROM TERMINAL:
echo ./chontoBash.sh NumMinutesToWork \"My Task to work in double quotes...\"
echo If not exist, chonto will create the log file log.chonto, csv file to make data analytics:
echo "TimeStamp, TotalMinutes, Task worked..., status: completed (FULL) or incomplete task (BREAK)"
echo "TimeStamp, TotalMinutes, Task worked..., status: completed (FULL) or incomplete task (BREAK)"
echo "TimeStamp, TotalMinutes, Task worked..., status: completed (FULL) or incomplete task (BREAK)"
echo .
echo .
echo .
}log_chonto_break (){
end_time=$( date '+%s' )
echo $(date +"%F %H:%M:%S"), $((($end_time - $1) / 60)) Mins, "$2", BREAK >> log.chonto
mplayer glass.ogg > /dev/null 2>&1
tput clear
echo "Unfinished task logged :("
tput cnorm
exit 1
}log_chonto (){
end_time=$( date '+%s' )
echo $(date +"%F %H:%M:%S"), $((($end_time - $1) / 60)) Mins, "$2", FULL >> log.chonto
mplayer glass.ogg > /dev/null 2>&1
tput clear
echo "Task finished logged :)"
tput cnorm
}print_timer (){
#center the timer text, centering the cursor in Y/2:X/2-((text length)/2)
tput cup $(($3/2)) $((($4/2)-($(expr length "$1 $2")/2)))
tput bold; tput setaf $((1 + RANDOM % 10)); tput rev; echo "$1$2"; tput sgr0;
}if [[ $# != 2 ]]; then
tput bold; echo Error in arguments...; tput sgr0;
echo
print_help
exit 1
fiif ! [[ $1 =~ ^[0-9]+$ ]]; then
tput bold; echo...how many minutes do you like to work?; tput sgr0;
echo
print_help
exit 1
fiMINS=$1
start_time=$( date '+%s' )tput civis
trap 'log_chonto_break "$start_time" "$2"' SIGINT
for (( MINSCount=1; MINSCount<=$MINS; MINSCount++))
do
for (( SECSCount=1; SECSCount<=60; SECSCount++))
do
tput clear
print_timer " $(($MINS-$MINSCount)) Minutes " "$((60-$SECSCount)) Seconds to rest... " "$(tput lines)" "$(tput cols)"
sleep 1
done
donelog_chonto "$start_time" "$2"
Todo el script se encuentra en https://github.com/Open-SAI/ChonToPom obviamente es libre, más que libre esta bajo una licencia MIT.
El nombre de Chonto...ya se imaginarán por qué es. Pomodoro en italiano es tomate, en estas tierras hay tomate...chonto, el software libre da la libertad de crear tecnología y cuando se hace, uno le pone el nombre que quiera, así también se exporta cultura.
{relatedminimal}
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:
-
Resultados - Taller "Cloud + Open Source + Azure"
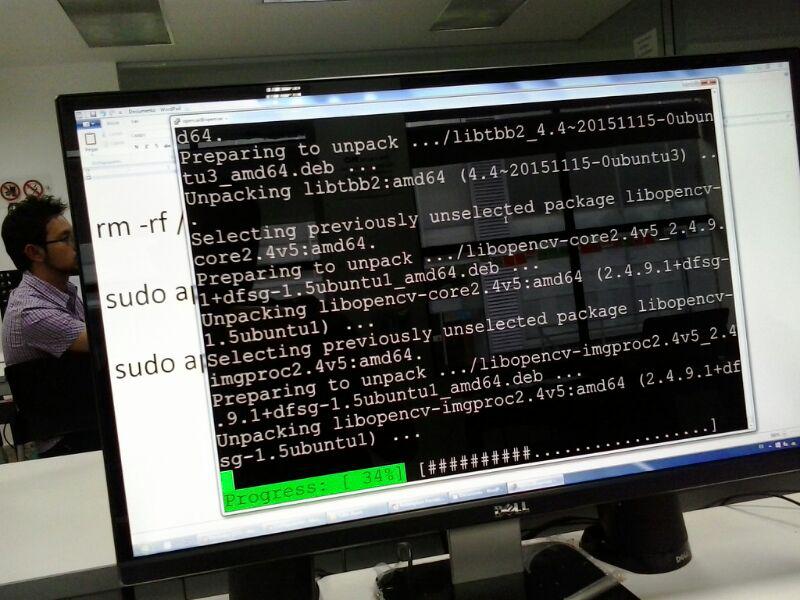
El pasado miércoles 25 de mayo una vez más en las instalaciones del Vivelab Bogotá llevamos a cabo el taller “Cloud + OpenSource + Azure” en el cual se dio a conocer a los asistentes las múltiples ventajas que tiene en la actualidad trabajar en la nube, y como Microsoft en los últimos años nos brinda una variada gama de herramientas Open Source listas para usar y que nos permite en unos cuantos pasos tener soluciones completas listas para trabajar.
Gracias a nuestros amigos de la ventanita, los asistentes al taller recibieron USD $100 para usar la plataforma Azure y durante el ejercicio reconocieron todas las funcionalidades que brinda esta para la creación de soluciones en la nube. Aprendimos a configurar y desplegar una maquina virtual Linux teniendo en cuenta los pequeños detalles de configuración tanto en Azure como en el mismo servidor Linux (Canonical - Ubuntu 16,04 LTS), aprendimos a actualizar nuestro sistema junto con algunos comandos básicos de administración e instalación de programas.
En seguida vimos como la nube no solo nos permite alojar sitios web, sino que también puede ser una fuente muy importante de poder de computo (procesamiento), para demostrarlo instalamos en el servidor la ultima versión del programa de modelado y animación Blender 3D, junto con una escena de prueba. Realizamos un render remoto que nos sirvió para reconocer los monitores de procesamiento y memoria con los que cuenta la plataforma Azure a la par que nos permitió poner a prueba su máxima capacidad de procesamiento con unos resultados bastante interesantes.
Para terminar decidimos desplegar un CMS donde los asistentes escogieron a Joomla el cual gracias a la gran variedad de proveedores dentro del marketplace se logro desplegar en tan solo unos cuantos pasos dejando nuestro sitio al aire y listo para trabaja sobre el.














Como siempre agradecemos al Vivelab Bogotá por toda su colaboración y a todos los asistentes al taller por acompañarnos.
Los esperamos en una próxima versión.
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario...y si te gustó nuestro contenido:

