
Durante los últimos meses, y particularmente en las últimas semanas, la atención en diversas redes sociales se ha enfocado en noticias sobre inteligencia artificial generativa y en fenómenos virales como las reinterpretaciones artísticas de imágenes al estilo del famoso estudio japonés de animación Ghibli:

Estas tendencias demuestran las capacidades de los nuevos modelos de inteligencia artificial generativa y cómo cada avance desata una competencia frenética e interesante por ver quién desarrolla el modelo más capaz, más rápido o más avanzado. Sin embargo, algo en lo que generalmente no reparamos, o quizás subestimamos, es que gran parte de las funcionalidades más avanzadas suelen estar tras un muro de pago. ¿Qué alternativas tenemos si deseamos explorar este nuevo mundo desde nuestro computador de escritorio o portátil?
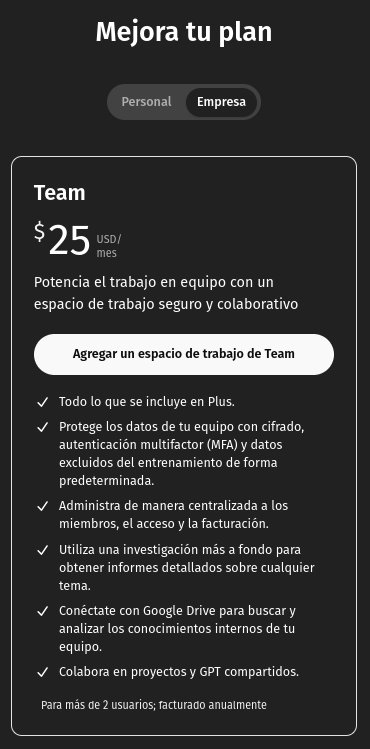 Primero, es importante saber que varios de estos modelos son de código abierto o derivan de modelos abiertos. Sin embargo, el hecho de que sean de código abierto no significa que sean fáciles de ejecutar. Muchos tienen un tamaño considerable, fácilmente superior a los 400 GB, y al ejecutarse podrían requerir más de 1 TB de VRAM (que es como se denomina a la memoria de las tarjetas gráficas GPUs). Generalmente, los computadores domésticos tienen un máximo de 8 GB de VRAM, haciendo casi imposible ejecutar modelos muy grandes, como el DeepSeek R1 de 671 mil millones de parámetros.
Primero, es importante saber que varios de estos modelos son de código abierto o derivan de modelos abiertos. Sin embargo, el hecho de que sean de código abierto no significa que sean fáciles de ejecutar. Muchos tienen un tamaño considerable, fácilmente superior a los 400 GB, y al ejecutarse podrían requerir más de 1 TB de VRAM (que es como se denomina a la memoria de las tarjetas gráficas GPUs). Generalmente, los computadores domésticos tienen un máximo de 8 GB de VRAM, haciendo casi imposible ejecutar modelos muy grandes, como el DeepSeek R1 de 671 mil millones de parámetros.
Afortunadamente, no todo son malas noticias. Actualmente existen modelos derivados mucho más pequeños gracias a técnicas como la destilación o la cuantización. Estas técnicas optimizan los modelos, reduciendo su tamaño y requisitos computacionales, aunque con menor precisión y menos parámetros disponibles. Por ejemplo, un modelo como el DeepSeek R1 de 671 mil millones de parámetros y aproximadamente 400 GB puede reducirse a un derivado como el deepseek-r1:1.5b, de tan solo 1.78 mil millones de parámetros y 1.1 GB, permitiendo su ejecución en casi cualquier computador moderno.
Pero entrando en materia: ¿cómo ejecutar estos modelos en nuestro computador de escritorio? Si tienes Linux, puedes hacerlo fácilmente usando Ollama, una herramienta de código abierto para ejecutar modelos de lenguaje grandes (LLMs) localmente.

Para instalar Ollama, abre una terminal y ejecuta:
curl -fsSL https://ollama.com/install.sh | sh
Este comando descargará e instalará Ollama. Luego, ejecuta el siguiente comando para iniciar el modelo:
ollama run deepseek-r1:1.5b
Ollama descargará y ejecutará el modelo automáticamente. En la página oficial de Ollama (https://ollama.com/search) encontrarás otros modelos y sus comandos correspondientes.
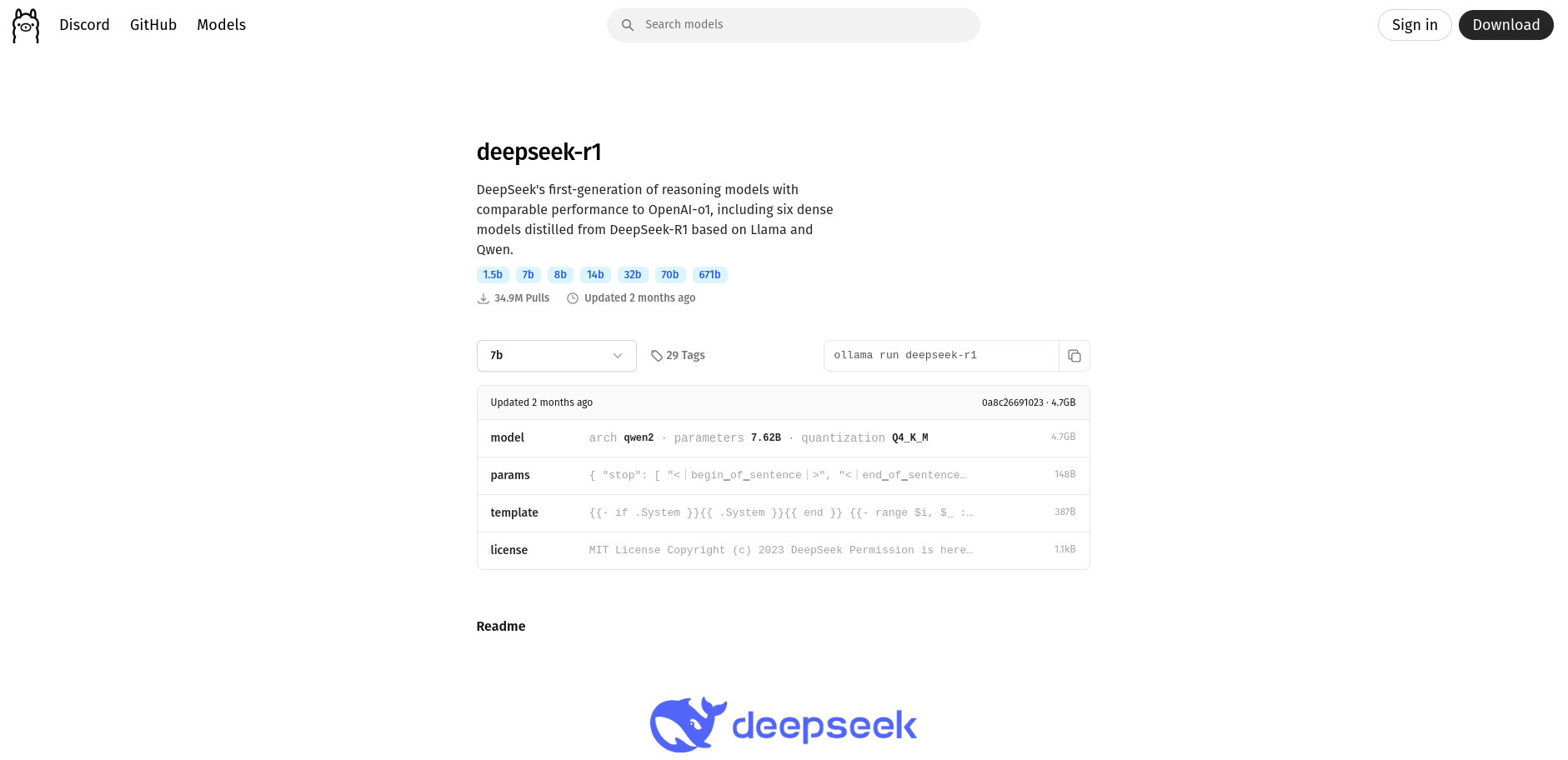
Ahora bien, quizás quieras usar un modelo más potente, como deepseek-r1:32b (32 mil millones de parámetros), que requiere mínimo 30 GB de VRAM. Aunque esto puede ser complicado o costoso, puedes utilizar la herramienta EXO de Exo Labs. Este software de código abierto permite crear un clúster de inteligencia artificial doméstico usando dispositivos cotidianos (PC, Mac, tablets, Raspberry Pi, etc.) conectados a la misma red, unificando sus capacidades de cómputo y VRAM mediante conexión P2P.
Para instalar EXO en Linux, ejecuta estos comandos en una terminal:
git clone https://github.com/exo-explore/exo.git cd exo pip install -e .
Luego, ejecuta este comando en cada dispositivo conectado a la red:
exo
Al hacerlo, EXO detectará automáticamente todos los dispositivos en la red, unificando sus recursos.
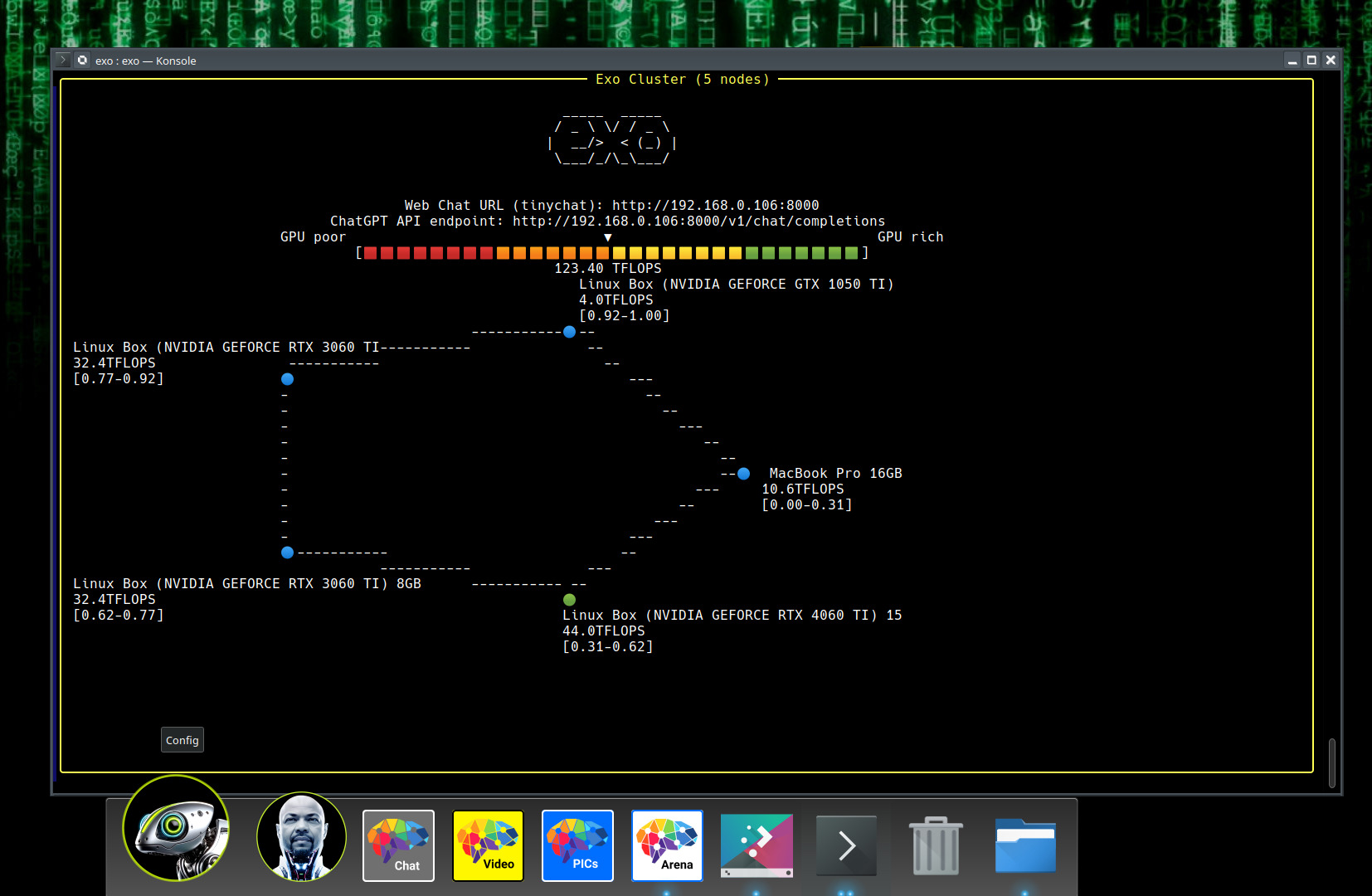
Luego podrás acceder a la interfaz web similar a ChatGPT visitando:
Allí, selecciona el modelo que desees utilizar y empieza a interactuar.
Finalmente, está el proyecto HART (Efficient Visual Generation with Hybrid Autoregressive Transformer), un modelo nuevo que genera imágenes en alta resolución (1024x1024), comparable en calidad con modelos avanzados de difusión. Usa una técnica novedosa llamada tokenizador híbrido, dividiendo la información de la imagen para mejorar calidad, velocidad y uso eficiente de recursos.

Para instalar HART en tu sistema, ejecuta estos comandos en una terminal:
git clone https://github.com/mit-han-lab/hart cd hart conda create -n hart python=3.10 conda activate hart
Instala CUDA si tienes una tarjeta NVIDIA:
conda install -c nvidia cuda-toolkit -y
Luego instala HART:
pip install -e . cd kernels && python setup.py install
Descarga otros modelos necesarios para HART:
git clone https://huggingface.co/mit-han-lab/Qwen2-VL-1.5B-Instruct git clone https://huggingface.co/mit-han-lab/hart-0.7b-1024px
Para usar HART con interfaz gráfica:
python app.py --model_path /ruta/al/modelo --text_model_path /ruta/a/Qwen2
Para generar imágenes desde la terminal:
python sample.py --model_path /ruta/al/modelo \ --text_model_path /ruta/a/Qwen2 \ --prompt "DESCRIPCIÓN DE LA IMAGEN" \ --sample_folder_dir /ruta/para/guardar/imagenes \ --shield_model_path /ruta/a/ShieldGemma2B
Ejemplo práctico:
python hart/sample.py --model_path hart-0.7b-1024px/llm \ --text_model_path Qwen2-VL-1.5B-Instruct \ --prompt "A little cat and dog playing in a sunny park with colorful flowers and a bright sky" \ --sample_folder_dir output_images --use_ema=False
Resultado:

Como puedes ver, hay diversas maneras de ejecutar potentes modelos de inteligencia artificial desde nuestros computadores locales, permitiéndonos explorar a fondo estas tecnologías sin costos adicionales.
Bonus Track:
Otra forma simple de poder ejecutar LLMs de manera local es simplemente instalando Alpaca una aplicación de código abierto que permite interactuar con modelos de inteligencia artificial (IA) de forma privada y local en dispositivos Linux. Utiliza Ollama para gestionar y ejecutar modelos de IA directamente en el dispositivo del usuario, garantizando que todas las conversaciones y datos se almacenen localmente sin depender de servicios en la nube.
Entre sus principales características se incluyen:
- Interacción con múltiples modelos de IA en una misma conversación.
- Gestión de modelos, permitiendo descargar y eliminar modelos directamente desde la aplicación.
- Reconocimiento de imágenes (disponible con modelos compatibles).
- Procesamiento de documentos de texto plano y PDFs.
- Importación y exportación de chats.
- Incorporación de transcripciones de YouTube y contenido de sitios web en las conversaciones.
Alpaca está disponible para su instalación a través de Flathub ejecutando los siguientes comandos:
flatpak install flathub com.jeffser.Alpaca
luego:
flatpak run com.jeffser.Alpaca
-
Como ves, la inteligencia artificial ya no es exclusiva de grandes centros tecnológicos; ahora está al alcance de tu computador personal. Con herramientas sencillas y accesibles, explorar el fascinante mundo de los modelos generativos es más fácil que nunca.
¿Y tú, ya has probado alguno de estos modelos en casa? Cuéntanos tu experiencia o qué modelo te gustaría probar primero. ¡Anímate a descubrir el poder de la IA desde tu escritorio!
En OpenSAI estaremos atentos a conocer tu experiencia, no dudes en dejar tu comentario ...y si te gustó nuestro contenido: