
Magazine
-
¿Cuánto vale una impresión 3D?
¿Cuánto cuesta un impresion 3D?
¿Cómo podemos calcular los costos de desarrollo de un prototipo o del servicio de impresión.?¿se cobra por minuto?
¿se cobra por gramo?
¿por la cara del cliente?
Con este vídeo daremos una guía con los elementos mínimos para determinar el costo de un impresión, ya sea para ofrecer el servicio o para la elaboración de un proyecto personal. Espero que el ejercicio permita visualizar sí estamos obteniendo ganancias por el uso de esta tecnología, o por el contrario, estamos perdiendo dinero por ignorancia.
{youtube}https://www.youtube.com/watch?v=lP2oZVUBluY{/youtube}
¿Cuánto vale una impresión 3D? -
Activar diferentes versiones de PHP en CentOS { Notas de Laboratorio }
Problema
- Por temas de desarrollo se requiere temporalmente activar una versión de php diferente a nivel global en un sistema CentOS
Solución Utilizada
DNF es el sistema de gestión de paquetes en Fedora (instalar/remover software del sistema), soporta la activación de módulos de paquetes con versiones específicas, permitiendo (p.ejp) usar distintas versiones de un lenguaje de programación sin tener problemas de dependencias:
- abrimos una terminal de comandos y revisamos las versiones disponibles de php:
- dnf module list php
- dnf module list php
- como es posible que se tenga otra versión seleccionada, primero se hace un reset:
- dnf module reset php
- dnf module reset php
- se especifíca la version requerida (p.ejp 7.4) y se instala:
- dnf module install php:7.4/common
- dnf module install php:7.4/common
- se puede confirmar la versión
- php --version
- php --version
- si se desea volver a la versión anterior por defecto, se puede repetir el procedimiento para la versión específica requerida.
Este procedimiento es muy útil para trabajar con versiones distintas de herramientas como nodejs, ruby, httpd, mariadb, maven, perl, python, postgresql y es una alternativa práctica a las SCL (Software Collections)
Imagen Original (CC Atribución)//man dnf: Module Command, server-world.info
-
Guía rápida de atajos para Blender 3D

Blender es hoy por hoy una de las herramientas de producción de contenidos 3D más importante en el mundo del código abierto. Con una gran comunidad de usuarios, se ha convertido poco a poco en una de las herramientas preferidas por los estudios de todos los tamaños a la hora de desarrollar animaciones, VFX, simulaciones e incluso videojuegos. Es por todo lo anterior que compartimos con ustedes esta pequeña guía de comandos que no pueden faltar a la hora de desarrollar tus proyectos con Blender 3D.
-
Lista de algunas herramientas de diseño libres
Complementando lo charlado el día sábado, con esta entrada quiera compartir un pequeño listado de aplicaciones para diseño gráfico y animación libres y sobre todo muy interesantes y potentes.
Scribus:
 Link oficial - http://www.scribus.net/canvas/Scribus
Link oficial - http://www.scribus.net/canvas/Scribus
Wikipedia - https://es.wikipedia.org/wiki/ScribusInkscape:
 Link oficial - http://inkscape.org/?lang=es
Link oficial - http://inkscape.org/?lang=es
Wikipedia - https://es.wikipedia.org/wiki/InkscapeMyPaint:
 Link oficial - http://mypaint.intilinux.com/
Link oficial - http://mypaint.intilinux.com/
Wikipedia - https://es.wikipedia.org/wiki/MypaintAlchemy:
 Link oficial - http://al.chemy.org/
Link oficial - http://al.chemy.org/
wikipedia - https://en.wikipedia.org/wiki/Alchemy_%28Open_Drawing_Project%29Krita:
 Link oficial - http://krita.org/
Link oficial - http://krita.org/
wikipedia - https://es.wikipedia.org/wiki/KritaGimp:
 Link oficial - http://www.gimp.org/
Link oficial - http://www.gimp.org/
wikipedia - https://es.wikipedia.org/wiki/GimpBlender:
 Link oficial - http://www.blender.org/
Link oficial - http://www.blender.org/
wikipedia - https://es.wikipedia.org/wiki/BlenderPencil:
 Link oficial - http://www.pencil-animation.org/
Link oficial - http://www.pencil-animation.org/
wikipedia - https://en.wikipedia.org/wiki/Pencil_%28software%29
Synfig: Link oficial - http://www.synfig.org/cms/
Link oficial - http://www.synfig.org/cms/
wikipedia - https://es.wikipedia.org/wiki/Synfig -
MicroImpresionismo - Pintura al óleo sobre vidrio reciclado (Artes Digitales Alternativas: Gimp)
El siguiente es un paisaje de la sábana de Bogotá, los cerros de Cota vistos hacia el norte desde una perspectiva de hierba. Está pintado con óleo sobre un espejo que alguna vez se recogió de la basura de una vidriería, tiene un tamaño de 5cm X 12cm:

Utilizando Gimp podemos jugar con los colores un poco para obtener el mismo paisaje justo antes de llover:

Y desde Gimp, utilizando el filtro globo giratorio, redimensionando, agregando un fondo de estrellas, desenfoque, y efecto de viento se obtiene algo parecido a una foto de planeta de una película tipo años ochenta:

-
Pipeline para la fabricación de contenido digital basado en Blender3D
Simplemente como referencia compartimos un esquema básico de un pipeline industrial con software libre para la creación de contenidos 3d:
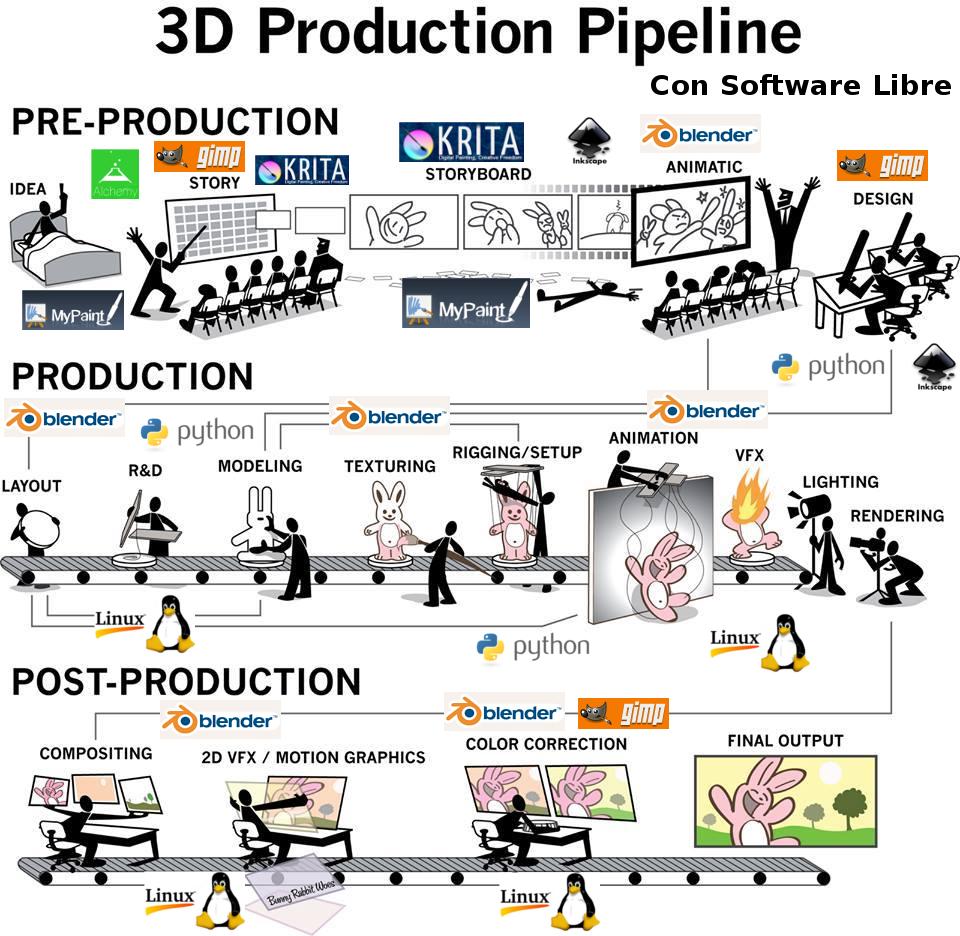
Obviamente pueden incluirse modificaciones...
-
Proyecto GOOSEBERRY
Conoce y apoya el Proyecto GOOSEBERRY de la Blender Foundation, la primera película animada totalmente libre y construida de manera colaborativa.

-
Qué es un Hackening
Según la Wikipedia un Happening es:
"... manifestación artística, frecuentemente multidisciplinaria, surgida en los 1950 caracterizada por la participación de los espectadores. Los happenings integran el conjunto del llamado performance art y mantiene afinidades con el llamado teatro de participación."
El Hackening se apoya en esa idea pero vincula las nuevas tecnologías de una forma absolutamente profana, busca trascender las clásicas reuniónes de geeks, ingenieros, o expertos en tecnología. El participante no es una entidad pasiva consumidora de información. Un Hackening no es una conferencia, no es un coloquio, no es un seminario. En un Hackening la tecnología se debe desnudar y los simples mortales se relacionan intimamente con ella. Un Hackening se parece a un hacklab pero en la plaza de mercado o en un club nocturno. En un Hackening la tecnología no es en sí misma el objetivo, sino más bien el medio para la creación colectiva y el resultado de dicha creación no se conoce al iniciar el hackening.
Para tener en cuenta:
- El espacio donde se realiza incluye elementos que generan un estimulo a los sentidos de diferentes formas (sonido, vídeos, comidas, bebidas, show's en vivo...)
- Conviene que el grupo de participantes sea totalmente heterogéneo y que no exista una mayoría distinguible o predominante de un área de conocimiento específica.
- Cada participante debería comprometerse a realizar una actividad basada en un trabajo propio, proyecto personal o tema de su interés
- La propuesta hecha por cada participante debería integrar la propuesta de otro participante, la coordinación para ello se debe realizar en el sitio del hackening durante su ejecución, y puede cambiar cuantas veces se desee durante todo el evento, sería ídeal si dicha integración de actividades ocurre entre profesionales de áreas distintas, ojalá de muy poca afinidad.
- Todos los participantes deberían estar a la vista de los demás para estar concientes de su participación.
- Uno o varios asistentes deberían actuar como cronistas, comprometiendose a generar un registro de las actividades y una recopilación de resultados que pueden no ser apreciados o detectados en primera instancia por los participantes activos.
- Debería existir un resultado o producto palpable que cada participante entrega al terminar (una imagen, un vídeo, un script, un párrafo escrito, una ruta de navegación en internet, un comentario a un blog en internet, etc).
- Es posible que se pueda programar el inicio de un Hackening pero no su finalización...
Ejemplos y características del trabajo realizado por los crónistas:
- gracias a la interacción entre varios participantes se detecta una idea o propuesta para una herramienta tecnológica que facilmente se expresa en un párrafo
- de la actividad de algunos participantes surge como resultado algún material gráfico, multimedia o similar que es abandonado al terminar pero recopilado por el cronista
- se ejecuto o realizó alguna configuración o secuencia de comandos de consola, se recopilan y comentan para garantizar que sea repetible lo realizado, lo ideal es que se publique en plataformas como github, así fuera algo muy básico...
- cronístas de áreas profesionales diferentes ofrecen perspectivas y registros diferentes (no es igual la historia contada por un ingeniero que por un experto de ciencías sociales).
- si varios cronistas registran en vídeo todo el evento, podría surgir un video total con una misma línea de tiempo, pero varias perspectivas del evento que podrían presentarse en algún tipo de pantalla dividida...
El objetivo del Hackening es hacer una integración activa y en tiempo real de distintos puntos de vista que en el día a día de cada participante no se presenta. Es común ver como profesionales y expertos de un área determinada unicamente tienen contacto con profesionales de su misma área o áreas áfines, esto podría verse como algo natural, pero puede generar problemas de -parcialidad-. Un ejemplo sería la definición de caos que un físico daría y la definición de ese mismo tema que ofrecería un biólogo o un sociólogo, los tres tendrían la razón y podrían dar una definición correcta del tema, hasta podrían coincidir en expresiones matemáticas que soporten su definición pero los matices deberían ser bien distintos. Sería interesante demostrar esto último usando un Hackening para ello.
Un beneficio inmediato del Hackening podría ser su papel como motor colectivo para la creatividad. Algunas ideas que hoy nos sorprenden han surgido de conexiones entre espacios de trabajo, perspectivas, o áreas que no son evidentes para la gran mayoría de nosotros.
Otro beneficio prodría ser la promoción de capacidades de "traducción de conocimiento" entre expertos de áreas totalmente distintas, o desde expertos hacia personas sin ningún tipo de preparación académica o experiencia profesional. Si un experto es capaz de explicar conceptos o ideas complicadas en un "discurso de asensor" a una persona que no posee formación académica o experiencia, puede ser algo muy positivo para un entorno social.